JUMP TO TOPIC
The Population Mean – Explanation & Examples
 The definition of the population mean is:
The definition of the population mean is:
“The population mean is the mean or average found in a population.”
In this topic, we will discuss the population mean from the following aspects:
- What is the population mean?
- How to find the population mean?
- The population mean formula.
- The role of the population mean.
- Practice questions.
- Answer key.
What is the population mean?
The population mean is the mean value of a numerical characteristic of the population. The population is the whole group of items we want to study. These items can be individuals, things, animals, plants, etc.
For example, the whole individuals living in the U.S., the whole chairs produced from a certain factory, the whole tigers living in rain forests in Indonesia, and the whole orange trees in Egypt.
These different populations’ numerical characteristics can be weights for individuals, leg lengths for chairs, tail lengths for tigers, and the heights for orange trees.
However, collecting information from the population may not be possible in many cases due to the great resources it needs.
For example, if we want to study the heights of American males. We can survey every American male and get his height. This is population data.
Alternatively, we can select 200 American males and measure their heights. This is sample data.
If we calculate the mean of the population data, its symbol is the Greek letter μ and pronounced “mu.”
How to find the population mean?
We have two cases:
- We have population data and so calculate the population mean from it.
- We have sample data and use the sample mean to construct an interval that most likely contains the population mean.
– Examples of population data
– Example 1
The following is the murder rate (per 100,000 population) for the 50 states of the U.S. in 1976. What is the mean of the murder rate?
We have information about all states of the U.S. so this is population data.
Note
This dataset may be considered as a sample or as a population.
It is a sample if we want to study the murder rate of the U.S. states in the 1970s, or it is a population if data is from 1970-1980 because this is a 1-year sample from these 10 years.
It is a population for the murder rate of U.S. states in 1976.
state | murder rate |
Alabama | 15.1 |
Alaska | 11.3 |
Arizona | 7.8 |
Arkansas | 10.1 |
California | 10.3 |
Colorado | 6.8 |
Connecticut | 3.1 |
Delaware | 6.2 |
Florida | 10.7 |
Georgia | 13.9 |
Hawaii | 6.2 |
Idaho | 5.3 |
Illinois | 10.3 |
Indiana | 7.1 |
Iowa | 2.3 |
Kansas | 4.5 |
Kentucky | 10.6 |
Louisiana | 13.2 |
Maine | 2.7 |
Maryland | 8.5 |
Massachusetts | 3.3 |
Michigan | 11.1 |
Minnesota | 2.3 |
Mississippi | 12.5 |
Missouri | 9.3 |
Montana | 5.0 |
Nebraska | 2.9 |
Nevada | 11.5 |
New Hampshire | 3.3 |
New Jersey | 5.2 |
New Mexico | 9.7 |
New York | 10.9 |
North Carolina | 11.1 |
North Dakota | 1.4 |
Ohio | 7.4 |
Oklahoma | 6.4 |
Oregon | 4.2 |
Pennsylvania | 6.1 |
Rhode Island | 2.4 |
South Carolina | 11.6 |
South Dakota | 1.7 |
Tennessee | 11.0 |
Texas | 12.2 |
Utah | 4.5 |
Vermont | 5.5 |
Virginia | 9.5 |
Washington | 4.3 |
West Virginia | 6.7 |
Wisconsin | 3.0 |
Wyoming | 6.9 |
1. Add up all of the numbers:
15.1+ 11.3+ 7.8+ 10.1+ 10.3+ 6.8+ 3.1+ 6.2+ 10.7+ 13.9+ 6.2+ 5.3+ 10.3+ 7.1+ 2.3+ 4.5+ 10.6+ 13.2+ 2.7+ 8.5+ 3.3+ 11.1+ 2.3+ 12.5+ 9.3+ 5.0+ 2.9+ 11.5+ 3.3+ 5.2+ 9.7+ 10.9+ 11.1+ 1.4+ 7.4+ 6.4+ 4.2+ 6.1+ 2.4+ 11.6+ 1.7+ 11.0+ 12.2+ 4.5+ 5.5+ 9.5+ 4.3+ 6.7+ 3.0+ 6.9 = 368.9.
2. Count the numbers of items in your population. In this population, there are 50 items or 50 states.
3. Divide the number you found in Step 1 by the number you found in Step 2.
The population mean = 368.9/50 = 7.378.
Note that the population mean has the same unit as the original data. So 7.378 is the mean murder rate per 100,000 population.
– Example 2
The following are the weights (in grams) for 71 chickens on a certain farm. What is the mean?
We have the weights of all chickens on the farm, so this is population data.
chicken number | weight |
1 | 179 |
2 | 160 |
3 | 136 |
4 | 227 |
5 | 217 |
6 | 168 |
7 | 108 |
8 | 124 |
9 | 143 |
10 | 140 |
11 | 309 |
12 | 229 |
13 | 181 |
14 | 141 |
15 | 260 |
16 | 203 |
17 | 148 |
18 | 169 |
19 | 213 |
20 | 257 |
21 | 244 |
22 | 271 |
23 | 243 |
24 | 230 |
25 | 248 |
26 | 327 |
27 | 329 |
28 | 250 |
29 | 193 |
30 | 271 |
31 | 316 |
32 | 267 |
33 | 199 |
34 | 171 |
35 | 158 |
36 | 248 |
37 | 423 |
38 | 340 |
39 | 392 |
40 | 339 |
41 | 341 |
42 | 226 |
43 | 320 |
44 | 295 |
45 | 334 |
46 | 322 |
47 | 297 |
48 | 318 |
49 | 325 |
50 | 257 |
51 | 303 |
52 | 315 |
53 | 380 |
54 | 153 |
55 | 263 |
56 | 242 |
57 | 206 |
58 | 344 |
59 | 258 |
60 | 368 |
61 | 390 |
62 | 379 |
63 | 260 |
64 | 404 |
65 | 318 |
66 | 352 |
67 | 359 |
68 | 216 |
69 | 222 |
70 | 283 |
71 | 332 |
1. Add up all of the numbers:
179+ 160+ 136+ 227+ 217+ 168+ 108+ 124+ 143+ 140+ 309+ 229+ 181+ 141+ 260+ 203+ 148+ 169+ 213+ 257+ 244+ 271+ 243+ 230+ 248+ 327+ 329+ 250+ 193+ 271+ 316+ 267+ 199+ 171+ 158+ 248+ 423+ 340+ 392+ 339+ 341+ 226+ 320+ 295+ 334+ 322+ 297+ 318+ 325+ 257+ 303+ 315+ 380+ 153+ 263+ 242+ 206+ 344+ 258+ 368+ 390+ 379+ 260+ 404+ 318+ 352+ 359+ 216+ 222+ 283+ 332 = 18553.
2. Count the numbers of items in your population. In this population, there are 71 items or chickens.
3. Divide the number you found in Step 1 by the number you found in Step 2.
The population mean = 18553/71 = 261.3 grams.
– Example 3
The following is the trunk circumference (in mm) for 35 orange trees on a certain farm. What is the mean?
We have the trunk circumferences of all trees on the farm, so this is population data.
tree number | circumference |
1 | 30 |
2 | 58 |
3 | 87 |
4 | 115 |
5 | 120 |
6 | 142 |
7 | 145 |
8 | 33 |
9 | 69 |
10 | 111 |
11 | 156 |
12 | 172 |
13 | 203 |
14 | 203 |
15 | 30 |
16 | 51 |
17 | 75 |
18 | 108 |
19 | 115 |
20 | 139 |
21 | 140 |
22 | 32 |
23 | 62 |
24 | 112 |
25 | 167 |
26 | 179 |
27 | 209 |
28 | 214 |
29 | 30 |
30 | 49 |
31 | 81 |
32 | 125 |
33 | 142 |
34 | 174 |
35 | 177 |
1. Add up all of the numbers:
30+ 58+ 87+ 115+ 120+ 142+ 145+ 33+ 69+ 111+ 156+ 172+ 203+ 203+ 30+ 51+ 75+ 108+ 115+ 139+ 140+ 32+ 62+ 112+ 167+ 179+ 209+ 214+ 30+ 49+ 81+ 125+ 142+ 174+ 177 = 4055.
2. Count the numbers of items in your population. In this population, there are 35 items or trees.
3. Divide the number you found in Step 1 by the number you found in Step 2.
The population mean = 4055/35 = 115.8571 mm.
– Examples of sample data
For samples with a size greater than 30, the interval that, most likely, contains the population mean is calculated by:
¯x±1.96Xs/√n
Where:
¯x is the calculated sample mean.
s is the standard deviation of the sample. It is a measure of the data spread.
n is the sample size.
This interval (called 95% confidence interval) gives us a range of possible values for the unknown population mean from which the sample was taken.
– Example 4
The following is the age (in years) of 50 randomly selected individuals from a certain population. If you know that this sample’s standard deviation is 18.65, construct a 95% confidence interval for the true population mean.
89 61 74 85 46 60 41 18 37 30 44 37 51 53 74 38 56 48 52 62 33 56 38 30 43 32 74 27 49 53 40 27 42 60 88 22 59 43 69 75 28 47 35 62 65 31 22 31 26 83.
1. Add up all of the numbers in your sample:
89+ 61+ 74+ 85+ 46+ 60+ 41+ 18+ 37+ 30+ 44+ 37+ 51+ 53+ 74+ 38+ 56+ 48+ 52+ 62+ 33+ 56+ 38+ 30+ 43+ 32+ 74+ 27+ 49+ 53+ 40+ 27+ 42+ 60+ 88+ 22+ 59+ 43+ 69+ 75+ 28+ 47+ 35+ 62+ 65+ 31+ 22+ 31+ 26+ 83 = 2446.
2. Count the numbers of items in your sample. In this sample, there are 50 items or persons.
3. Divide the number you found in Step 1 by the number you found in Step 2.
The sample mean = 2446/50 = 48.92 years.
4. The 95% confidence interval is:
¯x±1.96Xs/√n
¯x-1.96Xs/√n to ¯x+1.96Xs/√n
48.92-1.96X18.65/√50 to 48.92+1.96X18.65/√50 or 43.75 to 54.1.
It means that the true population mean age can be as small as 43.75 years and as large as 54.1 years.
Owing to the presence of the √n term in the formula for an interval calculation, the sample size affects the interval width. Larger sample sizes lead to smaller interval widths (or a more precise estimate of the population mean).
Suppose that you have a 100 sample size and you obtain the same sample mean and standard deviation; the 95% confidence interval will be:
48.92-1.96X18.65/√100 to 48.92+1.96X18.65/√100 or 45.26 to 52.6.
Suppose that you have a 500 sample size and you obtain the same sample mean and standard deviation; the 95% confidence interval will be:
48.92-1.96X18.65/√500 to 48.92+1.96X18.65/√500 or 47.29 to 50.55.
With increasing the sample size, you have more values about the true population mean.
We can see that in the following figure.
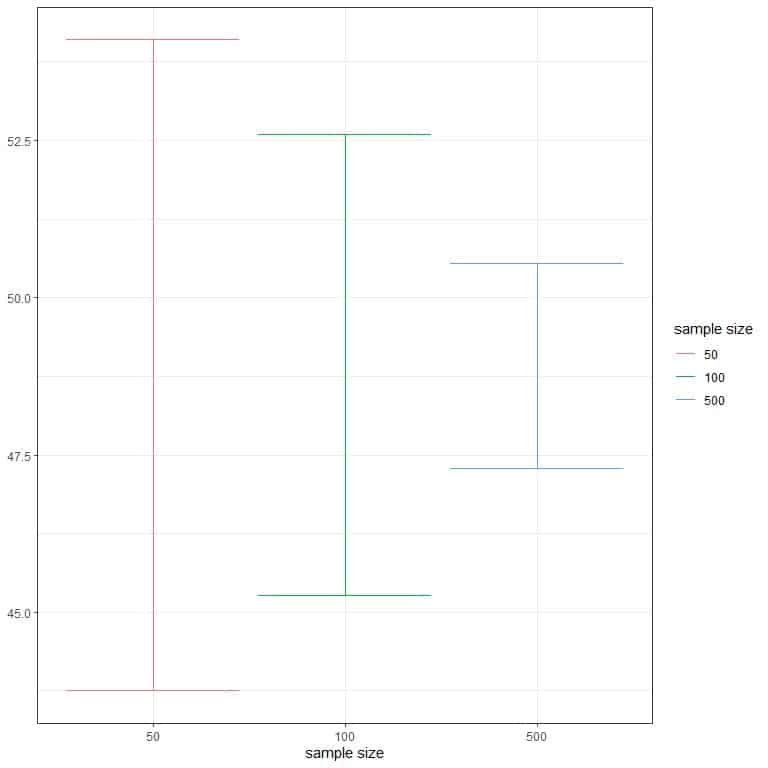
Increasing the sample size has led to a narrower confidence interval.
– Example 5
Plotting the confidence intervals for different random samples
We have a population data of more than 20,000 individuals. We know that the true population mean for the age of these 20,000 individuals is 47.18 years.
Using a computer program, we will take 50 random samples from this population, each of size 35, and calculate the mean’s confidence interval for each sample.
sample | mean | lower | upper |
1 | 44.71 | 39.98 | 49.45 |
2 | 48.43 | 41.72 | 55.14 |
3 | 46.66 | 40.25 | 53.06 |
4 | 48.43 | 42.17 | 54.68 |
5 | 48.77 | 42.26 | 55.28 |
6 | 47.14 | 42.04 | 52.25 |
7 | 46.74 | 40.67 | 52.81 |
8 | 51.49 | 44.65 | 58.32 |
9 | 49.20 | 42.29 | 56.11 |
10 | 50.14 | 43.71 | 56.58 |
11 | 44.23 | 37.17 | 51.29 |
12 | 49.37 | 42.91 | 55.83 |
13 | 40.97 | 35.80 | 46.15 |
14 | 50.06 | 44.05 | 56.07 |
15 | 46.09 | 40.22 | 51.95 |
16 | 40.60 | 35.55 | 45.65 |
17 | 47.80 | 41.69 | 53.91 |
18 | 49.89 | 43.17 | 56.60 |
19 | 47.40 | 42.58 | 52.22 |
20 | 51.17 | 44.40 | 57.94 |
21 | 45.20 | 39.59 | 50.81 |
22 | 48.29 | 42.30 | 54.27 |
23 | 48.26 | 42.87 | 53.65 |
24 | 42.91 | 37.93 | 47.89 |
25 | 42.49 | 36.14 | 48.83 |
26 | 47.86 | 43.42 | 52.30 |
27 | 43.66 | 38.07 | 49.24 |
28 | 43.14 | 37.61 | 48.68 |
29 | 45.54 | 39.69 | 51.40 |
30 | 48.51 | 42.45 | 54.58 |
31 | 45.57 | 38.80 | 52.34 |
32 | 46.11 | 40.18 | 52.05 |
33 | 45.03 | 39.37 | 50.69 |
34 | 47.71 | 41.44 | 53.99 |
35 | 49.14 | 42.61 | 55.67 |
36 | 46.37 | 40.30 | 52.44 |
37 | 47.91 | 41.95 | 53.87 |
38 | 46.91 | 41.16 | 52.67 |
39 | 49.77 | 44.45 | 55.09 |
40 | 40.86 | 35.95 | 45.77 |
41 | 49.00 | 42.68 | 55.32 |
42 | 45.43 | 40.00 | 50.85 |
43 | 50.83 | 44.84 | 56.81 |
44 | 45.77 | 39.29 | 52.25 |
45 | 44.89 | 39.27 | 50.50 |
46 | 43.43 | 37.98 | 48.88 |
47 | 43.43 | 37.78 | 49.08 |
48 | 51.26 | 45.15 | 57.36 |
49 | 48.94 | 43.31 | 54.57 |
50 | 46.43 | 39.95 | 52.91 |
Add another column to the table to indicate if the interval covers the true population mean.
The interval will not cover the population mean if the lower limit is higher than the population mean or the upper limit is lower than the population mean.
sample | mean | lower | upper | covers population mean |
1 | 44.71 | 39.98 | 49.45 | yes |
2 | 48.43 | 41.72 | 55.14 | yes |
3 | 46.66 | 40.25 | 53.06 | yes |
4 | 48.43 | 42.17 | 54.68 | yes |
5 | 48.77 | 42.26 | 55.28 | yes |
6 | 47.14 | 42.04 | 52.25 | yes |
7 | 46.74 | 40.67 | 52.81 | yes |
8 | 51.49 | 44.65 | 58.32 | yes |
9 | 49.20 | 42.29 | 56.11 | yes |
10 | 50.14 | 43.71 | 56.58 | yes |
11 | 44.23 | 37.17 | 51.29 | yes |
12 | 49.37 | 42.91 | 55.83 | yes |
13 | 40.97 | 35.80 | 46.15 | no |
14 | 50.06 | 44.05 | 56.07 | yes |
15 | 46.09 | 40.22 | 51.95 | yes |
16 | 40.60 | 35.55 | 45.65 | no |
17 | 47.80 | 41.69 | 53.91 | yes |
18 | 49.89 | 43.17 | 56.60 | yes |
19 | 47.40 | 42.58 | 52.22 | yes |
20 | 51.17 | 44.40 | 57.94 | yes |
21 | 45.20 | 39.59 | 50.81 | yes |
22 | 48.29 | 42.30 | 54.27 | yes |
23 | 48.26 | 42.87 | 53.65 | yes |
24 | 42.91 | 37.93 | 47.89 | yes |
25 | 42.49 | 36.14 | 48.83 | yes |
26 | 47.86 | 43.42 | 52.30 | yes |
27 | 43.66 | 38.07 | 49.24 | yes |
28 | 43.14 | 37.61 | 48.68 | yes |
29 | 45.54 | 39.69 | 51.40 | yes |
30 | 48.51 | 42.45 | 54.58 | yes |
31 | 45.57 | 38.80 | 52.34 | yes |
32 | 46.11 | 40.18 | 52.05 | yes |
33 | 45.03 | 39.37 | 50.69 | yes |
34 | 47.71 | 41.44 | 53.99 | yes |
35 | 49.14 | 42.61 | 55.67 | yes |
36 | 46.37 | 40.30 | 52.44 | yes |
37 | 47.91 | 41.95 | 53.87 | yes |
38 | 46.91 | 41.16 | 52.67 | yes |
39 | 49.77 | 44.45 | 55.09 | yes |
40 | 40.86 | 35.95 | 45.77 | no |
41 | 49.00 | 42.68 | 55.32 | yes |
42 | 45.43 | 40.00 | 50.85 | yes |
43 | 50.83 | 44.84 | 56.81 | yes |
44 | 45.77 | 39.29 | 52.25 | yes |
45 | 44.89 | 39.27 | 50.50 | yes |
46 | 43.43 | 37.98 | 48.88 | yes |
47 | 43.43 | 37.78 | 49.08 | yes |
48 | 51.26 | 45.15 | 57.36 | yes |
49 | 48.94 | 43.31 | 54.57 | yes |
50 | 46.43 | 39.95 | 52.91 | yes |
Then, we will plot these confidence intervals to see how they cover the true population mean.
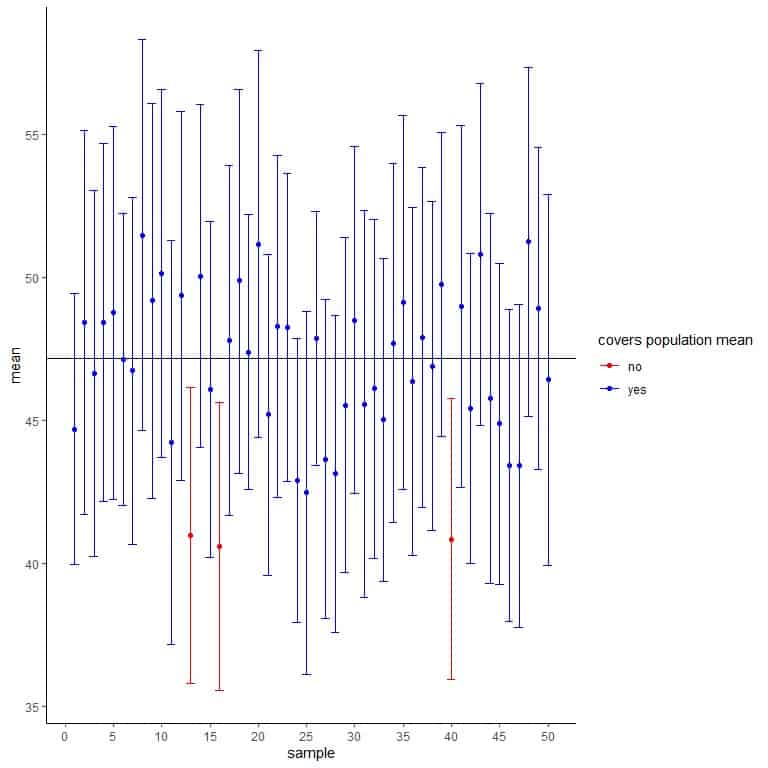
The horizontal black line represents the true population mean.
The blue or red dots represent the mean calculated from each random sample.
The error bars represent the confidence interval calculated from each sample.
We see only 3 samples create a confidence interval that does not cover the population mean and accounting for 3/50 = 0.06 or 6%. Hence, it is very unlikely that the created confidence interval does not cover the population mean.
In research, we take only 1 sample and construct a 95% confidence interval from it.
We do not know if our sample yields an interval containing the population value or one of the bad samples that yield an interval not containing the population value.
However, the constructed 95% confidence interval works 95% of the time. We can assume that the constructed interval has the population value.
Population mean formula
The population mean formula is:
μ=1/N∑X
Where μ is the population mean.
N is the population size.
∑X means the sum of every element in our population.
We used this formula in the above examples, where we summed the population data and divided it by the population size (or multiplied by 1/N).
The role of the population mean
The population mean gives us a measure of the center or central tendency of the population data.
This is useful when comparing different populations to each other.
– Example 1
The following table is the mean age for certain male and female populations.
sex | mean age |
Male | 54.78 |
Female | 54.69 |
We see that the mean age is nearly similar for males and females.
It means that the ages for males and females are similar in their distributions. We can see that from plotting the ages for both populations as histograms.
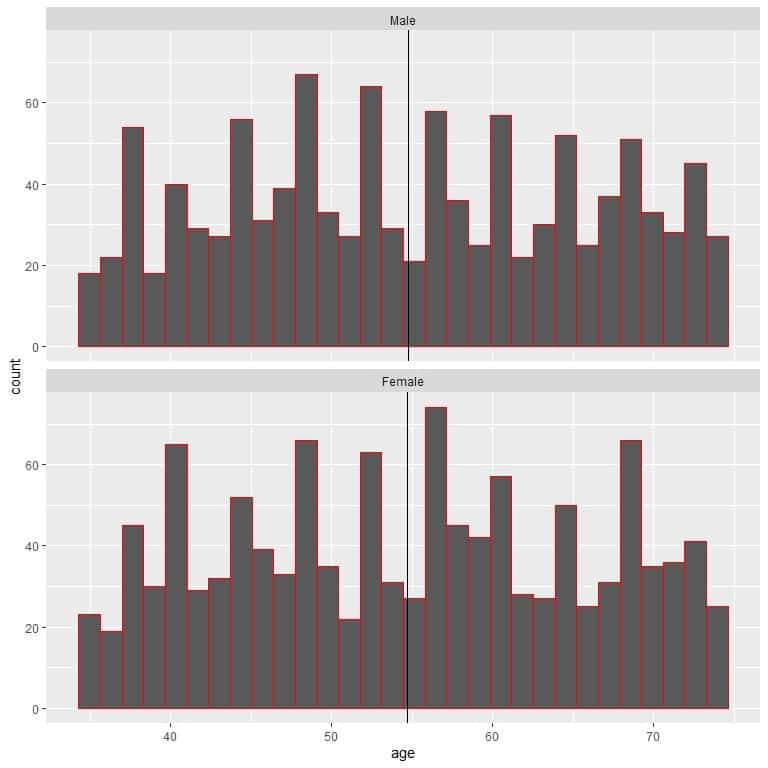 The black vertical line represents the mean for each group.
The black vertical line represents the mean for each group.
We can also plot the data as a dot plot to see individual values.
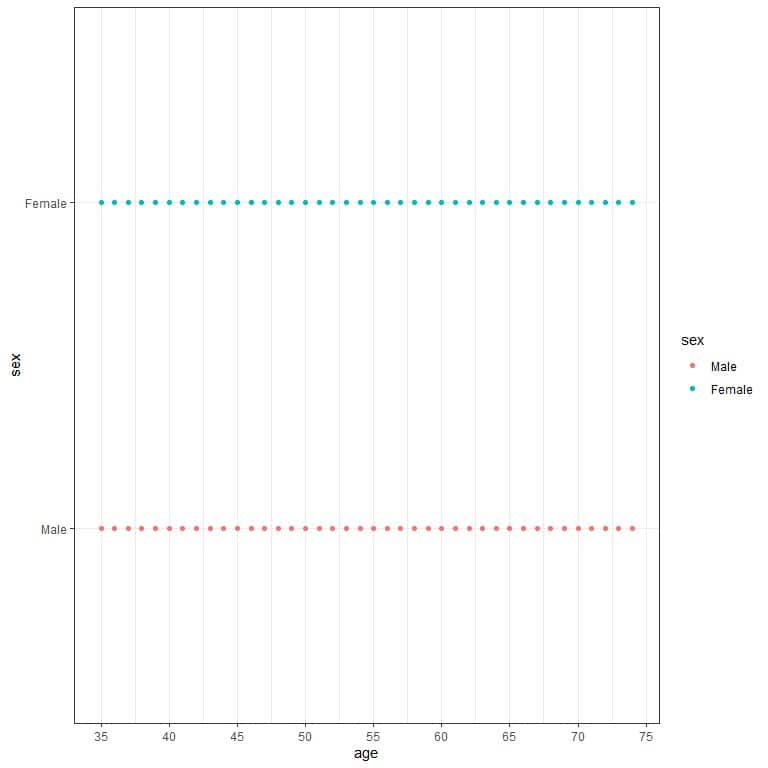
We see the same range for male and female ages.
– Example 2
The following table is the mean height for certain male and female populations.
sex | mean height |
Male | 169.27 |
Female | 156.99 |
We see that the mean height for males is higher than the mean height for females.
Without looking at the data, this male population’s heights are longer than the heights of this female population on average.
We can see that from plotting the heights for the 2 populations as histograms.
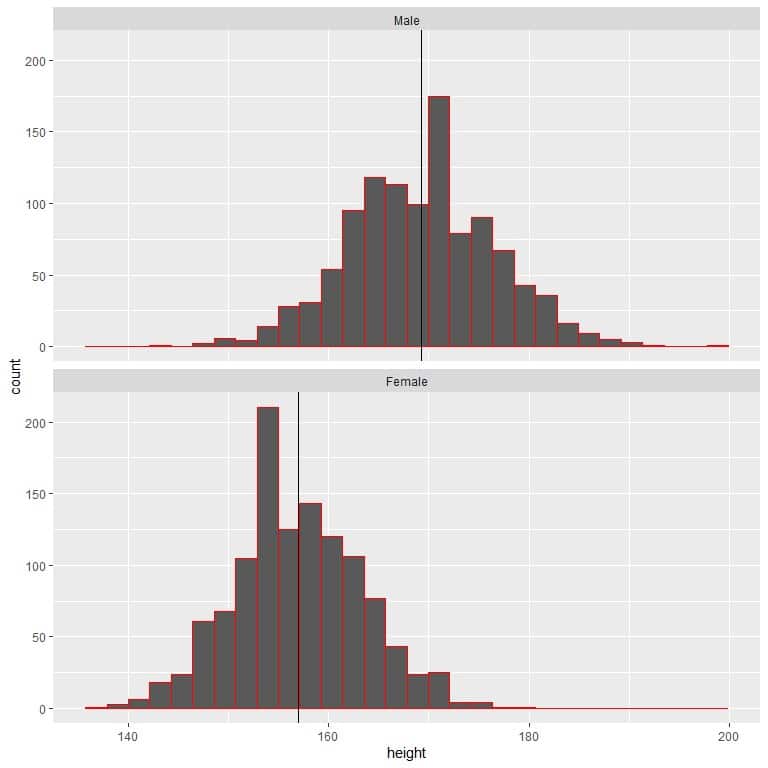
The black vertical line represents the mean for each group.
We can also plot the data as a dot plot to see individual values.
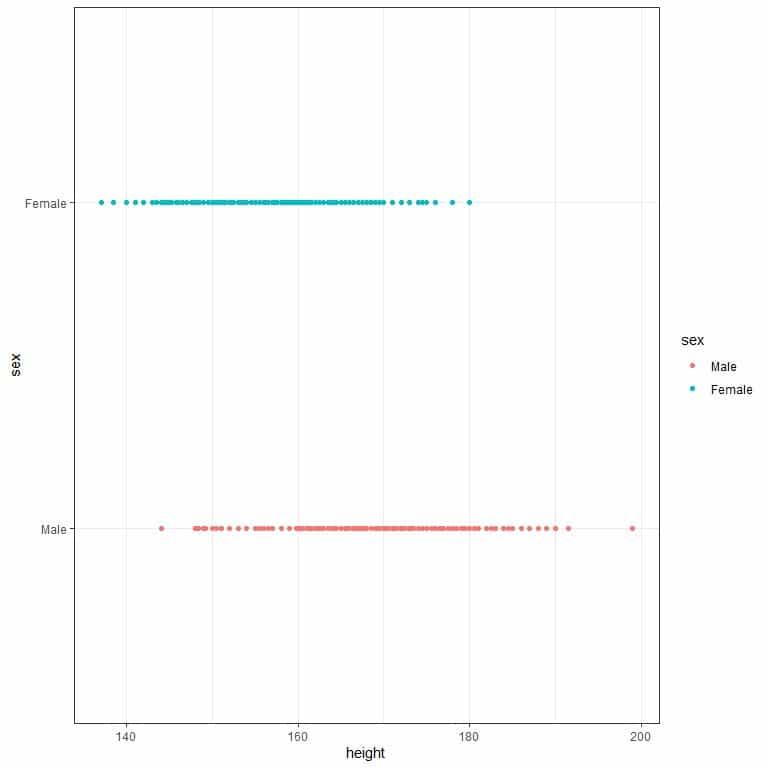
We see that males’ height tends to be longer than females’ height.
But what about the sample means?
The sample means also give information about the population data center from which the sample was collected.
However, we have to calculate the 95% confidence interval for each sample mean due to sampling error. Suppose the confidence intervals do not overlap for the two samples. In that case, we can deduce that the two populations (from which the two samples were taken) are significantly different from each other.
– Example 3
The following table is the birth weight of neonates (in grams) for a random sample of 35 smoking and 35 never-smoking mothers.
smoking | Never-smoking |
3374 | 3090 |
1928 | 3651 |
2977 | 3572 |
2410 | 2733 |
3884 | 2450 |
1928 | 2495 |
3940 | 1928 |
2466 | 3232 |
3203 | 1474 |
2187 | 3203 |
3317 | 1729 |
2381 | 3860 |
2821 | 3912 |
3321 | 3983 |
3629 | 3770 |
2782 | 2835 |
3260 | 4153 |
2769 | 1970 |
2466 | 1588 |
2353 | 3062 |
3042 | 2353 |
3637 | 2977 |
2466 | 4054 |
3005 | 3274 |
2414 | 3459 |
3651 | 1588 |
2948 | 2495 |
2977 | 2877 |
3430 | 2722 |
2126 | 2240 |
2367 | 3234 |
2125 | 3175 |
3856 | 4111 |
2906 | 3544 |
3132 | 2301 |
The mean birth weight for the smoking mothers = 2899 grams, while the mean for never-smoking mothers = 2946 grams.
The standard deviation for smoking mothers’ weight = 576.72 grams, while the standard deviation for never-smoking mothers = 783.22 grams.
While the sample mean for never-smoking mothers is larger than that for smoking mothers, one may argue that this difference is due to sampling error and not due to the true difference between the population of smoking and never-smoking mothers.
To overcome that, we construct a 95% confidence interval for each mean:
The 95% confidence interval for smoking mothers is:
2899-1.96X576.72/√35 to 2899+1.96X576.72/√35 or 2707.9 to 3090.1.
The 95% confidence interval for never smoking mothers is:
2946-1.96X783.22/√35 to 2946+1.96X783.22/√35 or 2686.5 to 3205.5.
The two confidence intervals overlap, so we conclude that there is no difference in the mean neonate birth weight for smoking and never smoking mothers.
Practice questions
1. The following is the income per capita for the 50 states of the U.S. in 1974. What is the mean income per capita?
state | Income |
Alabama | 3624 |
Alaska | 6315 |
Arizona | 4530 |
Arkansas | 3378 |
California | 5114 |
Colorado | 4884 |
Connecticut | 5348 |
Delaware | 4809 |
Florida | 4815 |
Georgia | 4091 |
Hawaii | 4963 |
Idaho | 4119 |
Illinois | 5107 |
Indiana | 4458 |
Iowa | 4628 |
Kansas | 4669 |
Kentucky | 3712 |
Louisiana | 3545 |
Maine | 3694 |
Maryland | 5299 |
Massachusetts | 4755 |
Michigan | 4751 |
Minnesota | 4675 |
Mississippi | 3098 |
Missouri | 4254 |
Montana | 4347 |
Nebraska | 4508 |
Nevada | 5149 |
New Hampshire | 4281 |
New Jersey | 5237 |
New Mexico | 3601 |
New York | 4903 |
North Carolina | 3875 |
North Dakota | 5087 |
Ohio | 4561 |
Oklahoma | 3983 |
Oregon | 4660 |
Pennsylvania | 4449 |
Rhode Island | 4558 |
South Carolina | 3635 |
South Dakota | 4167 |
Tennessee | 3821 |
Texas | 4188 |
Utah | 4022 |
Vermont | 3907 |
Virginia | 4701 |
Washington | 4864 |
West Virginia | 3617 |
Wisconsin | 4468 |
Wyoming | 4566 |
2. The following is the miles/U.S. gallon (mpg) for 32 car models in a certain car showroom (in the 1970s). What is the mean of this population?
model | mpg |
Mazda RX4 | 21.0 |
Mazda RX4 Wag | 21.0 |
Datsun 710 | 22.8 |
Hornet 4 Drive | 21.4 |
Hornet Sportabout | 18.7 |
Valiant | 18.1 |
Duster 360 | 14.3 |
Merc 240D | 24.4 |
Merc 230 | 22.8 |
Merc 280 | 19.2 |
Merc 280C | 17.8 |
Merc 450SE | 16.4 |
Merc 450SL | 17.3 |
Merc 450SLC | 15.2 |
Cadillac Fleetwood | 10.4 |
Lincoln Continental | 10.4 |
Chrysler Imperial | 14.7 |
Fiat 128 | 32.4 |
Honda Civic | 30.4 |
Toyota Corolla | 33.9 |
Toyota Corona | 21.5 |
Dodge Challenger | 15.5 |
AMC Javelin | 15.2 |
Camaro Z28 | 13.3 |
Pontiac Firebird | 19.2 |
Fiat X1-9 | 27.3 |
Porsche 914-2 | 26.0 |
Lotus Europa | 30.4 |
Ford Pantera L | 15.8 |
Ferrari Dino | 19.7 |
Maserati Bora | 15.0 |
Volvo 142E | 21.4 |
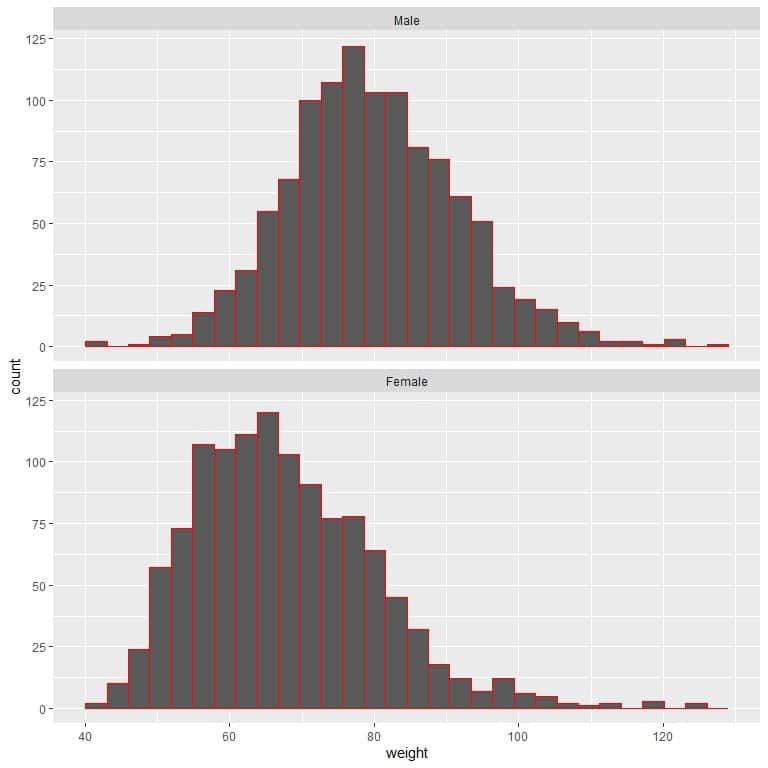
3. The following two histograms are for the weights of certain male and female populations. Can you deduce which population has a higher mean weight?
3. The following table is for the mean wind speed for different classes of storm populations.
class | mean |
hurricane | 85.97 |
tropical depression | 27.27 |
tropical storm | 45.81 |
And the following dot plot is for the data values (wind speed) of these classes.
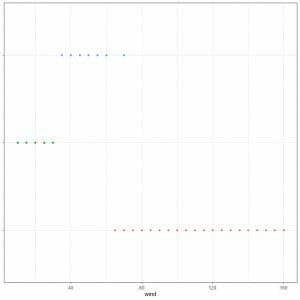
We have many data values, but as they are equal in value, the points are superimposed.
Which points correspond to which mean?
5. You have two samples of diamonds. One sample is 38 ideal-cut diamonds, and the mean weight is 0.703 grams, and the standard deviation is 0.4. The second sample is 45 fair-cut diamonds, and the mean weight is 1.25 grams, and the standard deviation is 0.5.
Assuming that the two samples are randomly selected from a certain batch of diamonds in a certain factory. Is there a difference in the mean weight between the ideal and fair-cut diamonds in this batch?
Answer key
1. This is population data so we can calculate the population mean directly:
- Sum of all numbers = 221790.
- Count the numbers of items in.your population. In this population, there are 50 items or states.
- Divide the first number by the second number.
The population mean = 221790/50 = 4435.8.
2. This is population data so we can calculate the population mean directly:
- Sum of all numbers = 642.9.
- In this population, there are 32 items or models.
- Divide the first number by the second number.
The population mean = 642.9/32 = 20.09 mpg.
3. We see that males’ weight tends to be heavier than females’ weight (more shifted to the right), so males’ mean weight will be larger than the mean weight for females.
4. Red points correspond to hurricane class, blue points to a tropical storm, and green points to a tropical depression.
It is because each group of dots’ center corresponds to the calculated mean value in the table.
5. We construct a 95% confidence interval for each mean:
The 95% confidence interval for the ideal-cut diamonds is:
0.703-1.96X0.4/√38 to 0.703+1.96X0.4/√38 or 0.58 to 0.83.
The 95% confidence interval for fair-cut diamonds is:
1.25-1.96X0.5/√45 to 1.25+1.96X0.5/√45 or 1.10 to 1.396.
The two confidence intervals do not overlap, so we conclude that fair-cut diamonds have a significantly heavier weight than ideal-cut diamonds in this batch.