JUMP TO TOPIC
Categorical Data – Explanation and Examples
Categorical data is data divided into set groups.
These groups often include categories such as sex, age range, income range, race, education level, and other personal statistics.
Categorical data plays a role in all areas of statistics, social sciences, and physical sciences.
This section covers:
- What is Categorical Data
- How to Analyze Categorical Data
- Categorical Data Definition
- Categorical Data Examples
What is Categorical Data?
Categorical data is qualitative data divided into set groups.
Recall that qualitative data is non-numeric data. It can also include numeric data divided into ranges.
Qualitative data includes any descriptive words. These can be descriptions about demographics such as age range, sex, race, city, employment section, etc. They can also be descriptions about animals such as coat color or litter size. Descriptions of homes, vehicles, cities, and plants also may include qualitative data.
Sometimes, qualitative data is coded as quantitative data. For example, months could be coded from $1$ to $12$ based on their order in the year.
Categorical data is different from qualitative data in that it includes set categories. This is like the difference between answering a multiple choice question and an open-ended question on a survey. Any data collected using multiple-choice options is categorical data.
Because of this, categorical data is easy to divide into frequency tables. These frequency tables are useful for calculating the joint and marginal frequency, which helps with analysis.
How to Analyze Categorical Data
Categorical data analysis is similar to qualitative data analysis.
When categorical data cannot be coded quantitatively, the mode is the best measure of the data set’s central tendency.
Frequency tables are one of the best displays for categorical day. They show how often each category appears and makes comparison easy. For instance, one could say that category A occurs twice as often as category B.
When each element in a data set contains two categorical data points, a two-way frequency table represents the data.
The two-way frequency table will show the responses broken down by totals in each category and totals for combinations of categories. This makes it easy to analyze common occurrences and common combinations.
Categorical Data Definition
Categorical data is a collection of data where possible responses are grouped together. These responses are typically qualitative data, but they can also include ranges of quantitative data.
The easiest way to tell whether data is categorical or not is to see if it would work in a frequency table. In some cases, non-categorical data can be coded as categorical data. This is especially true when dealing with ranges of numbers.
Categorical Data Examples
Demographic information entered on surveys, employment and enrollment records, and censuses are collected as categorical data.
For example, a medical school may analyze statistics about students who apply to their program. This information would help the school know who is interested in attending and shape future recruitment efforts.
The application for the school likely includes demographic information such as undergraduate major and undergraduate school.
Even though there are many possible undergraduate majors and undergraduate schools, there are finitely many. Most applications do not leave these questions open-ended. Rather, students will select their school and major from a list. Since, most applications are digital now, this information will be compiled and shared with the marketing office.
Then, displaying this information in a table could give the medical school unique insights. For example, it could show that while very few art majors applied, almost all of the applicants from a particular school were art majors, prompting the school to look into that program more deeply and see why.
It could show the medical school that many people from the local state school are interested in attending, so they may hold more recruitment events there. Similarly, they may see that they have lots of philosophy majors and start sending application information to the philosophy department at different schools.
Common Examples
This section covers common examples of problems involving categorical data and their step-by-step solutions.
Example 1
Identify whether the following questions collect categorical data questions or not. Explain your reasoning.
- How many hours a day do you spend watching television?
_____ hours. - How many hours a day do you spend watching television?
$0 – 1$ hours
$1 – 2$ hours
$2 – 3$ hours
$3 – 4$ hours
More than $4$ hours - What is your favorite television show? ________
- Describe your favorite kinds of shows to watch on television. _____
- What is your favorite television genre?
Comedy
News
Drama
Action
Family Entertainment
Other
Solution
Analyze the questions one at a time.
The first question is open-ended, so survey takers may enter any value they would like. This means that the data from this question is not categorical.
However, as the next question shows, responses could be easily coded as categorical. This second question includes five categories of responses, so it is categorical.
The next question is categorical because there are only finitely many television shows in existence. However, the number of shows is so extensive that there may not be a lot of overlap in people’s answers. In addition, since this is an open-ended response, people may list more than one answer, say they don’t have a favorite, or describe shows they like instead. Again, though, if there were a certain number of common responses, making these into categories just requires including less common responses through an “other” option.
Question four is an example of one that is not categorical but is also not easily converted to categories. This question asks for a description, which will likely be more than one word. There will probably be very few responses that are exactly the same.
In research that asks questions like this, sometimes researchers will “code” this data to make it easier to analyze. That is, they will find responses that are similar and group them together. This is a human task, however, and it is not easily done by AI.
Question five is a straightforward category question because it includes a set list of options. Note that having an option for “other” is okay since that is still a type of category.
Example 2
A diner sends out the following survey to some guests. Convert the questions from the survey into questions that provide categorical data.
- How was your service at the restaurant?
- What food did you order at the restaurant?
- How frequently do you go out to eat?
Solution
These questions are all open ended. This means customers can respond in one word or in a paragraph. To analyze this data then requires the restaurant to spend a lot of time grouping similar responses.
Asking categorical questions in the first place works better.
The first question could be changed to a ranking. “On a scale of $1$ to $5$ with $1$ being terrible and $5$ being perfect, rate the service your received at the restaurant.” These numbers are not meant to be continuous, but rather a code for the quality. Having only five options means this is categorical data.
It would also help for the restaurant to let survey takers fill in a bubble so that people do not rate it $4.3$ stars, making the data quantitative instead of qualitative.
The second question’s wording is unclear. If the restaurant is trying to find which entree the survey taker ordered, they should ask “What entree did you order?” and follow the question with a list of their entrees. If the diner had a very large number of options, they could include their most popular dishes an an option for “other.”
The last question also works better as a multiple choice. As currently written, a customer could write “Rarely” or “often” or “Every other Thursday but also some Saturdays and when my boss buys lunch.” But does rarely mean once per month or once per year? Does often mean daily or every other week?
A better version of the question offers frequency ranges such as daily, more than once per week, weekly, more than once a month, monthly, five to ten times per year, less than five times per year.
These versions of the question give the restaurant owners the information it is looking for more quickly.
Example 3
The data shows the results of a poll conducted regarding a proposed change to a local ordinance. Make a frequency table for the data and analyze it in context.
(yes, yes, no, no, no, yes, no, undecided, no, no, yes, no, yes, yes, yes, no, no, no, no, yes, no, yes, no, no, yes, yes, no, undecided, no, no).
Solution
The poll included $30$ responses which were presumably selected from a list of three options.
Of the responses, two were undecided, eleven were yes, and seventeen were no.
A frequency table for this data would include all three responses as column headings, the total for each response, and a column with the total number of responses. The order of the responses would not matter.
This means the frequency table would look like this:

The no answer has a clear majority. Even if the two undecided people decided to answer yes, there would still be more people opposing the change.
In addition, thirty people may be insufficient to properly determine how people in general feel about the change, depending on the size of the town.
Example 4
A university keeps track of how many students are in the five different colleges at the school (humanities, science, fine arts, engineering, and business). It also tracks how many students are on the honors track and how many are not. The results appear in the two-way frequency table.
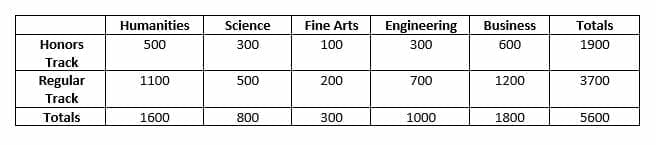
Analyze the two-way frequency table and the categorical data, making sure to answer the following questions:
- How many students attend the university?
- How many students are in the honors track?
- What is the most popular college within the university?
- What is the least popular college within the university?
- Which college has the highest percentage of honors track students?
Solution
Note that students in any of the colleges can be on the honors or regular track.
The total number of students at the university is the total number of students in each of the five colleges. This is the number in the bottom right corner. Therefore, the school has $5600$ students.
To find the total number of honors track students, add up the number of honors track students in each column. This is the number in the far right column of the honors track row, $1900$.
Next, the most popular college in the university will be the one with the most students while the least popular college will be the one with the fewest students. The total number of honors and regular track students in each college is the bottom number in the column corresponding to that college. In this case, the business college has the most students with $1800$ and the fine arts college has the fewest with $300$.
Finally, finding which college has the highest percentage of honors track students requires doing some additional calculations. The percentage is the number of honors track students in a college divided by the total number of students in that college. In this case, it is the first number in a column divided by the last number in that column.
For humanities, the percentage is $\frac{500}{1600} = 31.25%$.
For science, this is $\frac{300}{800} = 37.5%$.
In the fine arts college, $\frac{100}{300} = 33.33%$ of students are honors.
Next, in engineer, the percent is $\frac{300}{1000} = 30%$.
Finally, in the business school, $\frac{600}{1800} = 33.33%$ of students are in the honors college.
Since science had the highest percentage, this college has the highest percentage of honors students, even if it does not have the highest total number of honors students.
Example 5
A cola company analyzes how many units it sells at a local store. The company sells classic, orange, and vanilla flavors of its cola, and all three flavors are available in regular and diet. Create and analyze a two-way frequency table based on the categorical data given to describe the sales.
Note: c is class, o is orange, v is vanilla, r is regular, and d is diet in the list of data.
{(c, d), (c, r), (c, r), (o, r), (v, d), (v, r), (c, r), (c, r), (v, d), (o, r), (c, d), (c, d), (v, d), (c, r), (c, r), (c, d), (c, r), (o, r)}.
Solution
Begin making the table and filling in the column and row headings. In this case, make the columns the flavors and the rows diet/regular.
Next, begin filling out the table. The easiest cell to complete is the total number of sales. There are $18$ data points, so this number goes in the bottom right corner.
After that, it helps to find the data points that occur least frequently. In this set, that is the orange flavor. There were three orange flavored cola sales, and all of them were regular. Therefore, the orange column reads, from top to bottom, $3, 0, 3$.
Next, find the number of vanilla colas sold. There were only four sales, but they were a mix of diet and regular. Specifically, there were three diet sales and one regular sale. Therefore, the vanilla column will read $1, 3, 4$.
Finally, find the total number of classic colas sold. Since there were $18$ sales with $3$ orange and $4$ vanilla, there were $18-(3+4) = 11$ classic cola sales.
Of these sales, four were diet. The other seven must be regular then. Therefore, the classic column will read $7, 4, 11$.
To complete the frequency table, add up all of the regular colas sold and all of the diet colas sold. These totals will go in the last column in the corresponding row.
There are $7+3+1 = 11$ regular sodas and $4+0+3 = 7$ diet sodas sold.
Thus, the final frequency table looks like this:
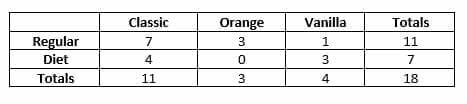
Looking at the frequency table indicates that orange was the least popular flavor and diet was the less popular type. The combined category diet orange was also the least popular with no sales at all.
On the other hand, diet vanilla was much more popular than regular vanilla.
Practice Problems
- Identify which of the following questions are categorical as is.
- What color is your couch?
A. Red
B. Blue
C. Green
D. Gray
E. Beige
F. White
G. Black - Where did you purchase your couch?
- How old is your couch?
- What is your favorite thing about your couch?
- How many cushions are on your couch?
A. 1-2
B. 3
C. 4
D. 5
E. 6+
- What color is your couch?
- Convert the following question into a question that provides categorical data.
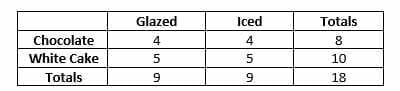
“Describe your ideal vacation.” - A bakery makes chocolate and white cake donuts. They ice some of their donuts but just glaze others. The bakery takes account of all of the donuts sold in one hour and gets the following results. Note that c is chocolate, w is white cake, g is glazed, and i is iced.
(c, i), (w, i), (w, i), (w, g), (w, g), (w, g), (w, i), (c, i), (c, g), (c, g), (c, i), (w, g), (w, g), (c, g), (c, i), (w, i), (w, i), (c, g).
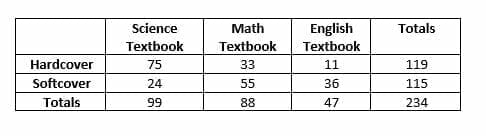
Make a frequency table for this data. - Analyze the following data table.

- A school analyzes how students use the given uniform. They can wear navy or khaki pants and red, white, or blue shirts. How many total categories of uniform combinations are there if each student wears one color of pants and one color of shirts each day?
Answer Key
- 1 and 5.
- (One option) Select your favorite type of vacation.
A. A relaxing beach escape
B. An adventurous mountain camping trip
C. A simple stay at a local landmark
D. A culture-infused trip to another country
E. Other 
- There are more science textbooks than any other textbook and significantly fewer English books than science or math books. There are similar total numbers of hardcover and softcover books, but the distribution among individual textbooks is different. In total, there were $234$ books int he data set with the largest number being hardcover science books and English hardcover books being the fewest.
- $6$ combinations.